Agent Debt: Don’t Trap Tomorrow’s Model in Today’s Prompt
It’s one thing to keep up with the latest models and best practices with your own personal workflows. It is another thing to keep an AI-powered product feature state of the art. Personal workflows can mostly adapt on the fly. User-facing features need evals, testing, and a higher degree of confidence that a model update did not inadvertently degrade the experience. This higher cost and the fact that most teams are unable to keep up is what creates agent debt.
Yet, the ground keeps moving with Anthropic and OpenAI averaging a new model release every 6-8 weeks. And the minor version number bumps can make the changes look smaller than they actually are. These are not just models getting a few percentage points better at the same tasks. As Anthropic research PM Alex Albert recently put it, each model version is treated like a product: the team decides what it should be good at. So every several weeks a new release shifts the boundary of what is now possible, what is reliable, and what your prompts need to work around.
For product owners, this creates a practical problem: how do you keep shipping high-quality AI features when what you’re building on keeps changing? The advice from Alex and others is to not over-engineer your prompts to the current model limitations. You should reduce the scaffolding you build to compensate for model weaknesses and optimize for intent instead. The idea is to sacrifice some short-term wins for longer term maintainability as the model will only get better.
While I agree in principle, in truth, I have found it almost impossible to follow. As a product owner, I want to give my users the best experience possible. And right or wrong, I view my prompt engineering around model quirks as part of our secret sauce: the thing that takes a 70% solution to 90% and makes us meaningfully better than the competition.
That said, I’ll admit there is real pain in building long, byzantine prompts. You either delay model updates given the large surface area to validate (nevermind that you are likely missing proper evals), or you update without touching your prompt and miss both the regressions and new capabilities. Unfortunately, prompts with a lot of scaffolding don’t just compensate for model weaknesses; ironically, they can preserve weaknesses too. Sean Goedecke captured this well in his post: prompts are technical debt too.
The crux of the problem is not just that our prompts are long. It’s that they are entangling two very different things. Read any hard-won prompt and you’ll find instructions describing the essence of a feature modified by scaffolding compensating for a model flaw:

To pick on just one of the scaffolds in the example above, “without asking a clarifying question”, might be useful when the current model overuses questions as a way to hedge and misdirect. But on a stronger model, that same instruction can prevent the model from recognizing when one missing detail would produce a much better answer.
Break It Down: Feature Contract + Model-Specific Fork

So what’s the solution? The key is to stop treating your prompt as one thing. Split it into two parts: a feature contract and a model-specific prompt.
A feature contract is the idealized, model-independent prompt for the feature. It is where you write down what this AI feature does - its essence: What is the user trying to accomplish? What does success look like? What context and evidence matter? Where are the boundaries? The contract should describe the goal, not how to achieve it. It captures the feature promise that remains true even when the model underneath it changes.
For some features this contract will be enough to get great outcomes, today. Ship it as your prompt. For others, you will need to make tweaks and add scaffolding to reach your performance bar. That’s fine; don’t lower your bar. The key though is to not do this in the contract. Instead fork a model-specific prompt and experiment there.
A Workflow for Model-Specific Prompts
The nice thing is you do not have to discover every model behavior from scratch. OpenAI and Anthropic publish prompting guidance for new model releases (see OpenAI’s GPT-5.5 guide and Anthropic’s Claude 4.7 guide). These guides are basically migration notes: what the new model is better at, what old scaffolding might now be counterproductive, and which knobs are worth revisiting around verbosity, reasoning effort, tool use, formatting, and completion criteria.
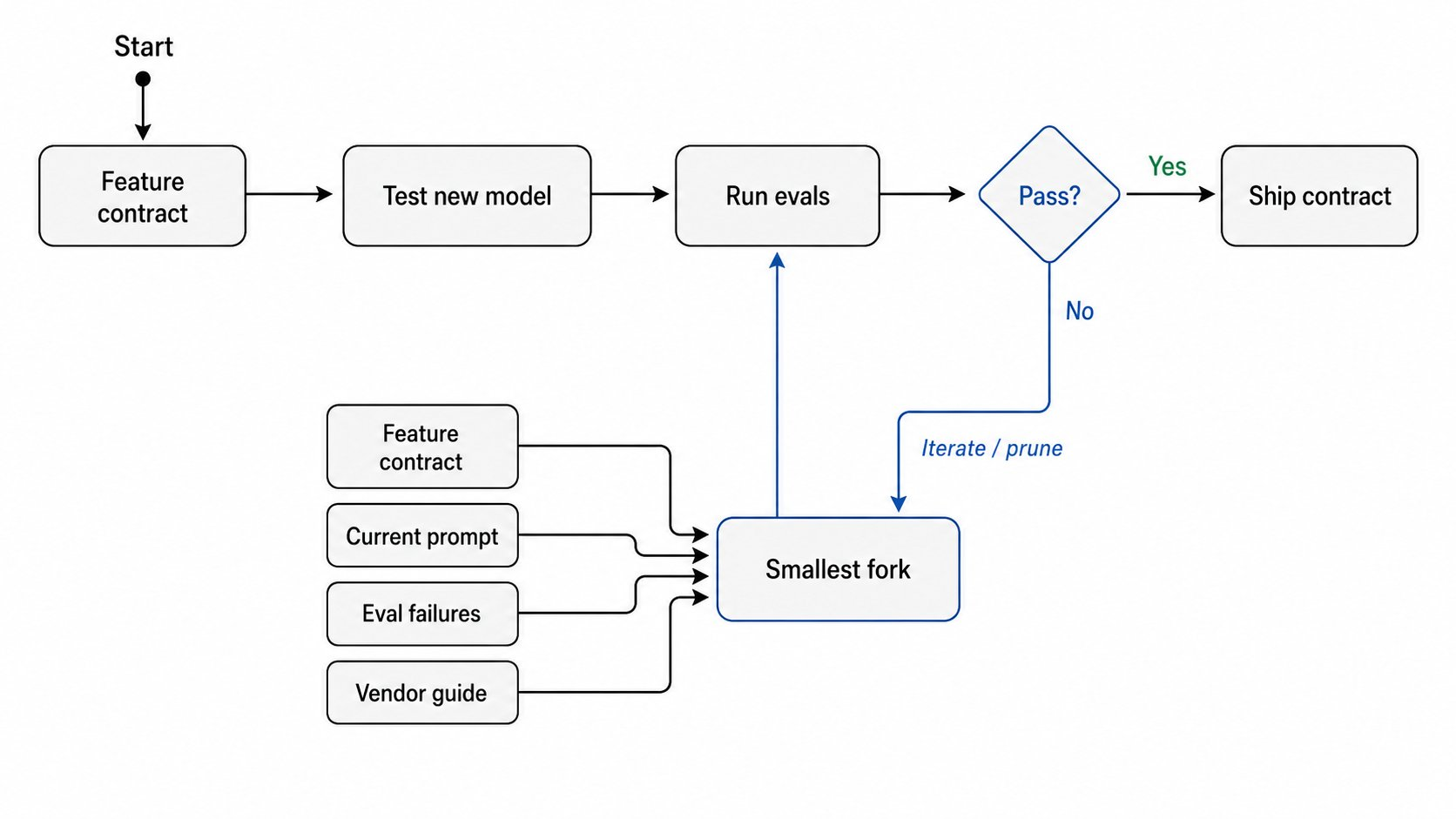
That means the first draft of the new prompt can be generated fairly efficiently. The trick is to give your agent the right inputs and ask it to create the smallest target-model fork that satisfies the contract and your evals.
The workflow is:
-
Test the new model against the feature contract alone. If it clears your quality bar, ship the contract as the prompt. No fork needed.
-
If it falls short, generate the smallest new model fork. Give your agent the feature contract, the current prompt, eval failures or production issues, and the relevant vendor prompting guide. The goal is not to port the old prompt forward. It is to preserve what still helps, delete stale scaffolding, and add only what the target model needs.
-
Test the fork against your evals. Pay special attention to the cases the old scaffolding was protecting and the behaviors the vendor guide suggests may have changed.
The useful discipline is to keep the contract separate from the model-specific fork. It is fine for the model-specific prompt to contain whatever scaffolding is necessary to achieve your quality bar. But when a new model ships, you start again from the contract, not from the existing fork. The old fork is useful as a reference for problems you previously had to solve, but it is just context, not the starting point.
So in summary, your feature contract should preserve the product promise: what the user is trying to accomplish, what success looks like, and what boundaries matter. Your model-specific prompt should be allowed to take on scaffolding: tuned, tested, deleted, and rewritten as the models improve.
Ultimately, this gives product teams a middle path. You do not have to sacrifice quality today, and you do not need to be trapped by scaffolding that is too hard to tear down. Keep the contract pure. Build the model-specific fork to meet your quality bar. With each new model, make the scaffolding prove itself again.