The AI Eval Flywheel: Scorers, Datasets, Production Usage & Rapid Iteration
Last week I attended the 2025 AI Engineer World’s Fair in San Francisco with a bunch of other founders from Seattle Foundations.
There were over 20 tracks on specific topics, and I went particularly deep on Evals, learning firsthand how companies like Google, Notion, Zapier, and Vercel build and deploy evals for their AI features.
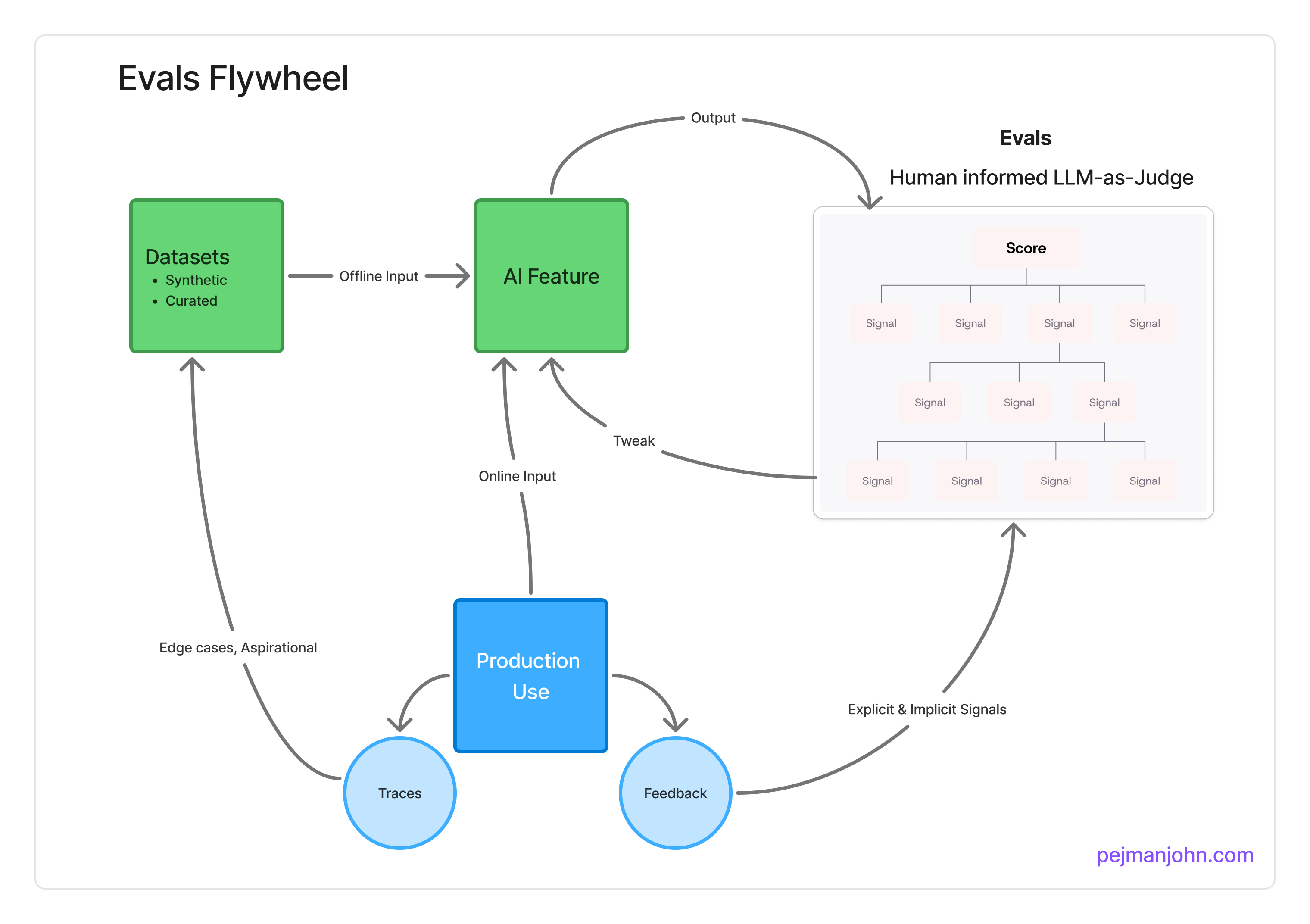
While there were meaningful unique details in each talk, there was also surprising consistency on the general framework which I’m representing with this flywheel below:
Beyond Vibes
So what does AI feature development look like without evals? It’s really just going off vibes.
 You are ad-hoc in the inputs you put into it as well as how you judge the output. If you’re building a chat bot, you might riff on a few messages and get a feel for the responses from your AI bot, and after some back and forth deem it shippable. But what happens when a new model launches or when you detect an edge case where you want to tweak your prompts? What you’ll find is there are too many permutations to keep track of, particularly with a non-deterministic system, and that you’ll want to be more systematic in how you improve and evolve your feature.
You are ad-hoc in the inputs you put into it as well as how you judge the output. If you’re building a chat bot, you might riff on a few messages and get a feel for the responses from your AI bot, and after some back and forth deem it shippable. But what happens when a new model launches or when you detect an edge case where you want to tweak your prompts? What you’ll find is there are too many permutations to keep track of, particularly with a non-deterministic system, and that you’ll want to be more systematic in how you improve and evolve your feature.
Little eval and Big Eval
This is where Evals come into play. First thing to mention is that people use the term “evals” in two different ways. There is a broader process of evals (big E) and there is also a specific step within that process (little e).
The specific step is in systematically grading the outputs of your feature. As we’ll unpack this more below but for any given output you might score it (73 out of 100) based on a weighted sum of specific output characteristics.
The broader process is what I capture in the flywheel above. The heart of it is on grading outputs, but it’s also about being structured with inputs, filtering & curating production usage, and ultimately iterating quickly and systematically on the AI Feature to drive improvements.
Evals: Scoring & Signals
One of the more interesting talks was by Pi Labs which is founded by former Googlers, David Karam and Achint Srivastava, who both worked on search.
They talked through Google’s process for assessing the quality of search results for a given query. Google essentially breaks down what a good search result is into 300 distinct signals. For example, the page speed could be a signal, how many & quality of backlinks, the quality of the writing, the page design, how directly it answers the specific query, etc. Each of these are a unique signal that could be automatically judged either by code or more recently by LLMs. Ultimately you do a weighted sum of these signals to arrive at a score for the given search result, and Google sorts its search results based on these scores.
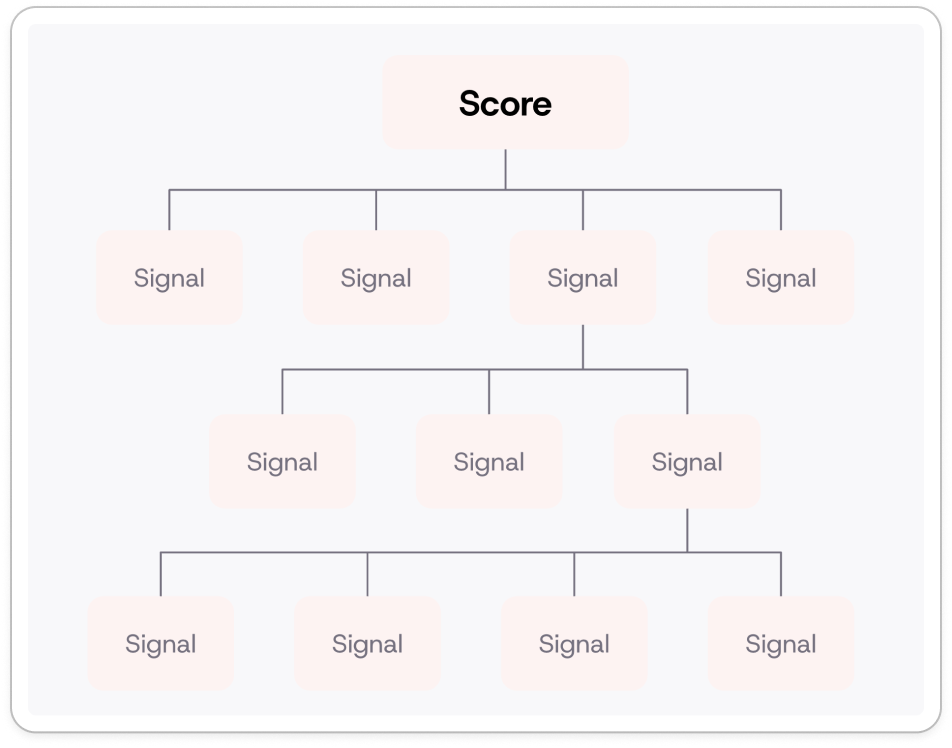 Pi Labs’ premise is that while AI features have some unique challenges (namely their non-determinism) the evaluation should work exactly the same way. For a given AI Feature you need to think deeply about what the characteristics (or signals) of a good output are and then build a way to automatically assess it as a Pass or Fail using one of two methods:
Pi Labs’ premise is that while AI features have some unique challenges (namely their non-determinism) the evaluation should work exactly the same way. For a given AI Feature you need to think deeply about what the characteristics (or signals) of a good output are and then build a way to automatically assess it as a Pass or Fail using one of two methods:
- Code-Based: Works best on hard measures like site speed, correct formatting - things that can be measured with code
- LLM as Judge: Works best on soft measures like natural language quality or style. Here you are writing a prompt for this characteristic that takes the feature output as an input.
Notion, Zapier and Vercel all effectively use this same idea of decomposing an AI feature into distinct signals and summing them to arrive at score per output.
A few other important points here:
-
You might wonder how do you know if your signal scorers are any good? Here the general advice is to have a set of human expert hand-graded examples. So for “quality of writing” you would have humans with strong writing skills manually evaluate a sample of outputs. You then evaluate your automated scorer against the human assessments and tweak accordingly. Yes this is evaluating your evals 🤣
-
Also why Pass vs. Fail instead of scoring each signal on a scale like 1-5 for quality of writing? Mostly it comes down to forcing clearer thinking. Hamel Husain breaks this down well in this tweet:
This tweet could not be embedded. View it on Twitter instead.
- Figuring out good signals for your feature is a non-trivial exercise. Pi Labs is trying to automate this process by automatically generating signals based on your output.
How do you actually build this?
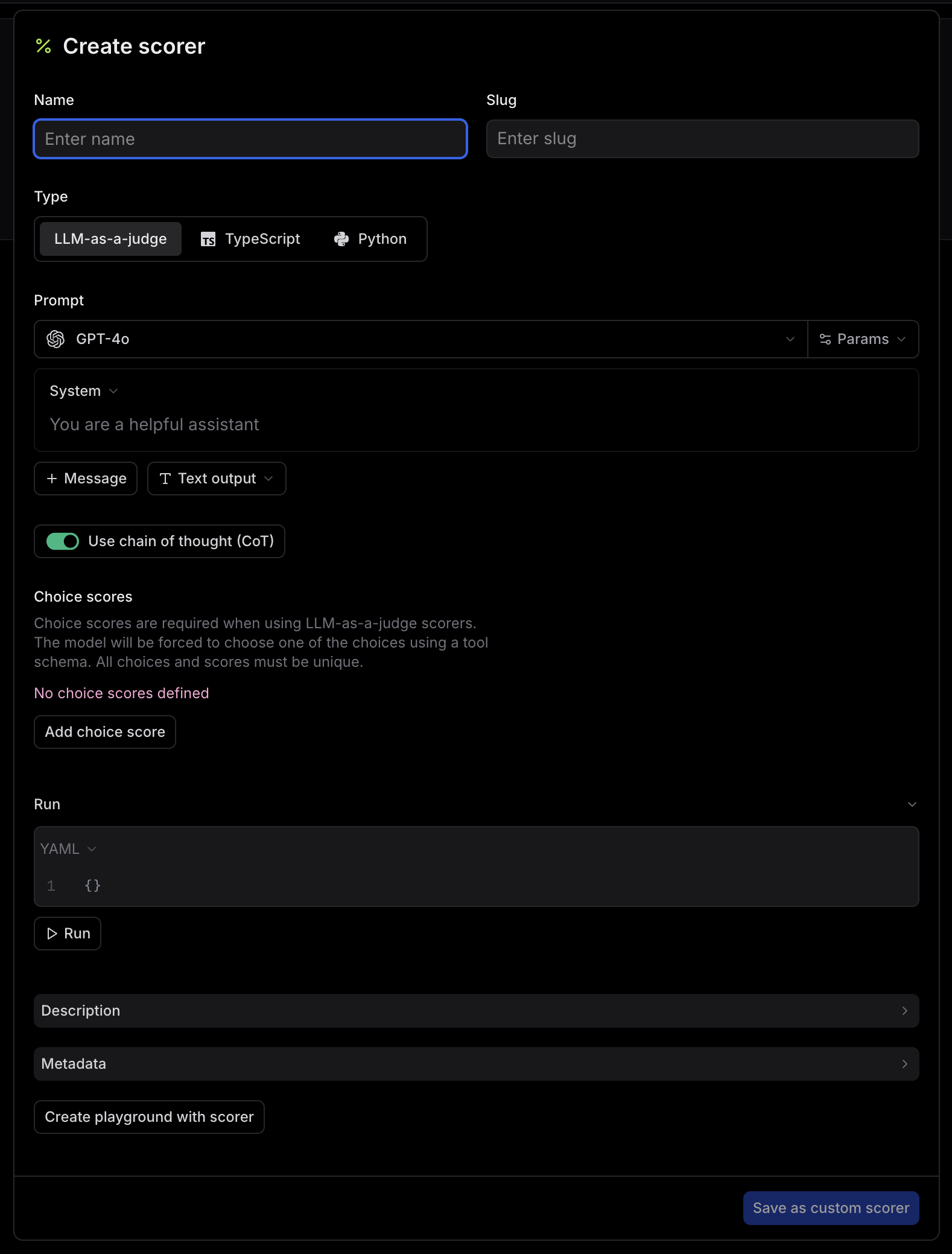
You could always build this custom or you could use a platform dedicated to this process.Braintrust seems to be the leader in evals as Notion, Zapier and Vercel all use them. While I’m not going to do a deep-dive on building the above, I just wanted to drop a pointer for those wondering on how to get started.
Here’s Braintrust “Create scorer” form for creating a LLM-as-judge or code-based eval.
Datasets: Getting Structured with your Inputs
It’s also important to get more systematic with the inputs you use to test your AI feature. This is where datasets come in. Datasets are just a collection of inputs you have saved for quick reuse. Generally there are two ways of going about putting together a dataset:
-
Curated: You handpick good inputs that represent a good breadth of what’s in-scope for this feature. You can either generate these yourself or if you have online evals (explained later) you can adopt real-life inputs from users. Some teams segment into many different curated datasets. For example you may have a “Base” dataset for basic coverage, “Edge Cases” for challenging cases, and even “Aspirational” for ones you don’t expect to pass yet but would like to pass eventually.
-
Synthetic: Here you get help from an LLM to generate inputs. This works especially well if you have defined your signal scorers above. You can feed those signals into your prompt and ask for examples that should pass or fail on specific signals and save those as a dataset.
Going Online: Filtering and Curating Production Usage
The talks kept using a term I didn’t grasp at first: the difference between an offline vs. online eval. The difference is in where the inputs are coming from. With offline, this is part of your development process and you are using datasets created by your team.
Online evals on the other hand means that you take some or all of your production usage of an AI feature and eval it directly. Here the users are driving the inputs. Online evals are great because they give you a heartbeat on how your feature is performing with real usage. They can help you detect regressions as well as understand the limitations of your datasets and evals.
Online evals also allow you to bring in other signals, particularly around user feedback and behavior.
-
Explicit: You may ask users to thumps-up or thumbs-down an output from your AI Feature. This is a helpful signal. For example you may see a “Thumbs Down” when your eval score on the output is high. This might be a sign that your evals are incomplete and there’s another signal that you need to be assessing.
-
Implicit: These are behaviors that indicate the AI feature delivered a positive experience. For example, does the user save, copy or share the output? Or maybe usage is correlated with increased retention or upgrades.
Ultimately you want to be using online evals to improve your overall process. This includes finding new traces such as edge cases or aspirational cases that you want to adopt into your offline datasets, as well as evolving your evals to more accurately capture the behaviors you’re seeing with actual users.
Putting it All Together: Frictionless Experimentation
Okay, so if you’ve read this far, the flywheel diagram should now make more sense. There’s been two areas of focus above:
- Structuring your inputs and how you evaluate your outputs
- Evolving your inputs and evals based on real production usage
The third big idea is to make it as quick and frictionless as possible to go through this flywheel. The more iterations you can make, the better the experience you can deliver for your users as you can confidently make and ship experiments. And since production usage is a key driver of this flywheel, it is truly a network effect type phenomenon where with the right process you can have your feature improve the more people use it.
One of the key ideas here is to have “playgrounds” to make it quick to tweak your feature and run it against your datasets and evals. You can handle some of this directly in platforms like Braintrust where you can encapsulate the key parts of your feature, allowing you to switch model providers or tweak prompts without any code commits.
Further Resources on Evals
One of the resources I’m considering is Hamel Husain and Shreya Shankar’s course on “AI Evals for Engineers & PMs”. From the free content they’ve been putting out it seems to be a good primer on the bleeding-edge of AI eval best practices.
Eugene Yan has also put out a number of great posts on Evals and is a good follow on X.
Finally, the conference has published a number of the talks I attended. Here’s the Zapier and Vercel talks as well as a few others I missed on the Eval track: https://www.youtube.com/watch?v=Vqsfn9rWXR8&t=1820s
5 Minute Video on this Post
I presented the ideas in this post at a Seattle Foundations meetup. Here’s my 5 minute talk: